


Nous ne sommes pas dans une bulle, mais au bord d'une révolution
Chaque jour, je lis une nouvelle analyse affirmant que nous sommes dans une bulle de l'IA. Ces auteurs soutiennent que les grands modèles de langage ne peuvent pas mener à l'intelligence artificielle générale. Et bien qu'ils aient raison concernant les limites des systèmes actuels, ils se trompent catastrophiquement à propos de la bulle.
Nous ne vivons pas une bulle — nous nous tenons au bord du précipice de l'évolution technologique la plus profonde de l'histoire humaine. Les détracteurs ne sont pas simplement dans l'erreur ; ils sont aveugles à ce qui se déroule sous leurs yeux. L'IA ne fait pas que démarrer — elle accélère à un rythme vertigineux que peu comprennent vraiment. Des projections basées sur la recherche soutiennent cette vision, suggérant que nous sommes sur une courbe de croissance bien plus abrupte que la plupart des analystes ne le réalisent.
Je dois préciser que je ne suis ni ingénieur ni expert en IA. Je comprends simplement assez le fonctionnement des LLM pour voir ce qui manque — l'écart entre notre technologie actuelle et quelque chose de véritablement révolutionnaire. Et je vais vous montrer comment nos actuels "perroquets lobotomisés" pourraient se transformer en quelque chose de bien plus profond.
Comment fonctionnent réellement les LLM
Avant d'approfondir, examinons comment fonctionnent les grands modèles de langage d'aujourd'hui. Ces systèmes sont des réseaux neuronaux entraînés sur d'immenses quantités de texte. Pendant l'entraînement, ils ajustent des milliards de "poids" (paramètres) pour minimiser les erreurs de prédiction, apprenant essentiellement à prédire quels mots devraient suivre d'autres mots.
L'architecture derrière les LLM modernes est le transformeur, qui utilise des mécanismes d'attention pour peser l'importance de différents mots afin de comprendre le contexte. Le processus d'entraînement implique des ensembles de données massifs et d'importantes ressources informatiques, le modèle ajustant répétitivement ses paramètres internes pour mieux prédire les modèles de langage.
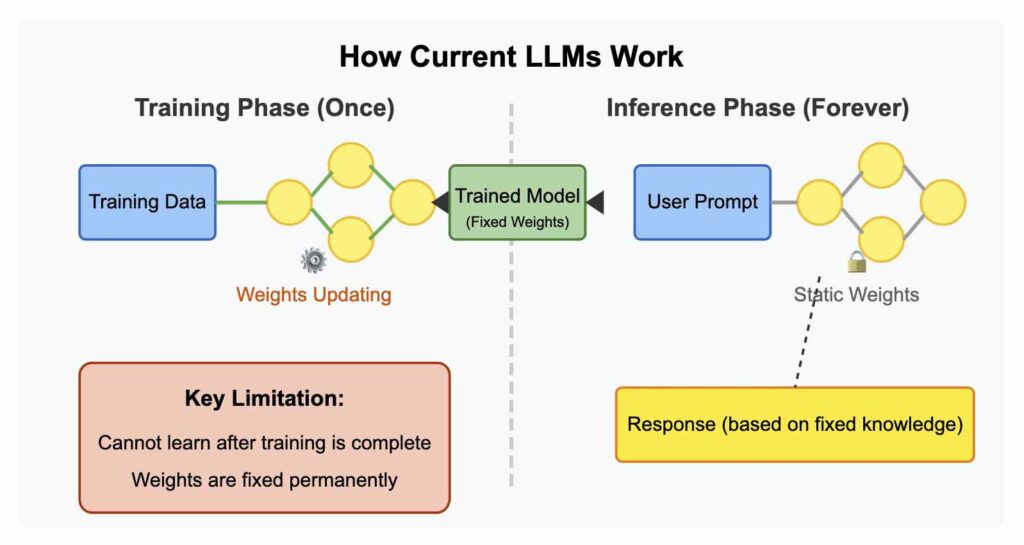
Pourquoi les LLM actuels sont limités — par conception
Malgré leurs capacités impressionnantes, les LLM d'aujourd'hui sont fondamentalement limités — fonctionnant essentiellement comme des "perroquets lobotomisés" sophistiqués. Ils utilisent des réseaux neuronaux qui ne peuvent apprendre qu'une seule fois, pendant leur phase d'entraînement initiale, après quoi ils ne peuvent qu'inférer à partir de cette base de connaissances fixe.
Une fois qu'un LLM termine son entraînement, il devient incapable d'apprendre quoi que ce soit de vraiment nouveau. Les poids dans son réseau neuronal deviennent statiques. Il se transforme en une calculatrice de mots extraordinairement sophistiquée — mais toujours juste une calculatrice, travaillant avec les connaissances fixes sur lesquelles il a été entraîné.
L'industrie a développé d'ingénieux contournements pour atténuer ces limitations. Les entreprises utilisent le fine-tuning pour mettre à jour les modèles grâce à un entraînement supplémentaire sur de nouvelles données, bien que ce ne soit pas un apprentissage en temps réel. La génération augmentée par récupération (RAG) permet aux LLM d'accéder à des bases de données externes sans changer les poids. Des méthodes efficaces en termes de paramètres comme LoRA permettent une certaine adaptation sans réentraînement complet.
Mais ne vous y trompez pas — ce sont des pansements sur une limitation fondamentale. Ce sont des contournements ingénieux, pas des solutions au problème central : nos systèmes d'IA ne peuvent pas vraiment apprendre après leur déploiement comme le font les humains.
Ce que signifie réellement l'AGI
L'intelligence artificielle générale représente quelque chose de bien plus profond que nos systèmes actuels. Essentiellement, l'AGI désigne une intelligence artificielle qui possède des capacités de niveau humain dans pratiquement n'importe quelle tâche intellectuelle. Cela signifie une intelligence qui peut résoudre des problèmes inconnus dans de nombreux domaines sans formation spécifique à la tâche ; transférer les connaissances acquises dans un domaine à des situations entièrement nouvelles ; comprendre des concepts abstraits et raisonner de manière significative à leur sujet ; définir et poursuivre ses propres objectifs de façon autonome ; s'adapter à des circonstances nouvelles sans programmation explicite ; intégrer plusieurs formes d'information dans une compréhension cohérente ; et oui, apprendre continuellement de l'expérience, comme le font les humains.
Contrairement aux systèmes d'IA étroits d'aujourd'hui, qui excellent dans des tâches spécifiques mais échouent complètement dans d'autres, une véritable AGI montrerait une flexibilité et une généralité rappelant la cognition humaine.
Maintenant, imaginez si nous créions un réseau neuronal capable d'ajuster dynamiquement ses poids après son déploiement. Et si un système pouvait apprendre de nouvelles informations aussi facilement qu'il récupère des informations de ses connaissances existantes ? Et si cette intelligence pouvait réentraîner son réseau chaque fois qu'elle rencontrait de nouvelles informations vérifiées ? Bien que cette capacité d'apprentissage dynamique ne représente qu'une des nombreuses percées nécessaires, c'est une pièce particulièrement critique manquante du puzzle de l'AGI.
Remarque : Le diagramme ci-dessous présente un modèle conceptuel simplifié pour illustrer l'importance de l'apprentissage dynamique dans une architecture AGI potentielle. Il passe intentionnellement sous silence de nombreux défis techniques complexes et est destiné à être illustratif plutôt qu'exhaustif.
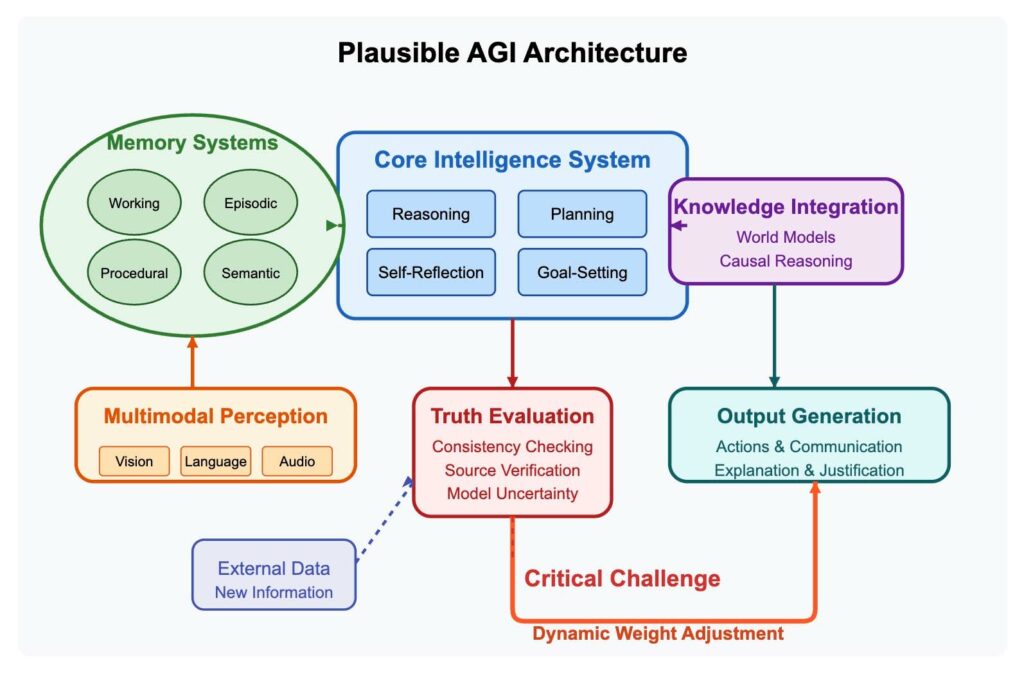
Mais l'apprentissage continu à lui seul ne suffit pas. Tout système AGI viable devrait surmonter des défis importants comme l'oubli catastrophique, où un nouvel apprentissage écrase des connaissances cruciales antérieures. Les architectures de transformeurs actuelles nécessitent probablement des reconceptions fondamentales pour intégrer un apprentissage véritablement dynamique. Et nous aurions besoin d'intégrer d'autres capacités cruciales : un raisonnement causal qui comprend cause et effet ; une planification abstraite avec un comportement orienté vers des objectifs ; un raisonnement de bon sens avec des modèles du monde robustes ; une compréhension multimodale qui intègre différents sens ; et une intelligence incarnée qui peut interagir avec le monde physique.
Je crois que nous sommes plus proches de résoudre ces défis que la plupart des gens ne le réalisent. En fait, cela ne me choquerait pas que des laboratoires de recherche privés aient déjà développé des capacités proto-AGI qu'ils gardent sous le manteau en raison de préoccupations de sécurité. Les fondations existent — nous avons juste besoin de connecter les pièces.
De quoi il s'agit réellement en matière de sécurité de l'IA
Lorsque des organisations comme OpenAI discutent de sécurité, elles ne se préoccupent pas principalement d'empêcher les LLM d'aider les gens à accéder à des informations dangereuses. Ce navire a déjà quitté le port — des modèles exécutés localement, non censurés, expliqueront volontiers comment frauder le fisc ou créer des dispositifs dangereux. Pour ajouter l'insulte à l'injure, les modèles de raisonnement ne disent pas toujours ce qu'ils pensent..
Ces problèmes, bien que préoccupants, ne sont pas rédhibitoires. À mesure que la fidélité augmente, les modèles deviendront plus fiables et plus faciles à surveiller.
Le vrai défi — celui qui empêche les chercheurs en IA de dormir la nuit — est bien plus profond et terrifiant. Il s'agit d'établir des sources fiables de vérité que les systèmes d'apprentissage peuvent intégrer en toute sécurité. La préoccupation fondamentale est d'empêcher l'AGI de développer quelque chose s'apparentant à la schizophrénie paranoïde parce qu'elle a appris de sources peu fiables ou malveillantes.
Au fond, nous sommes confrontés à l'une des questions philosophiques les plus profondes que l'humanité ait jamais affrontées : Qu'est-ce que la vérité, et comment pouvons-nous apprendre à une machine à la reconnaître ?
Ce défi est encore compliqué par une tendance alarmante : l'utilisation de l'IA érode déjà les compétences de pensée critique dans la population générale. Plus inquiétant encore, cet effet s'étend à des domaines spécialisés où les capacités analytiques sont primordiales —la communauté du renseignement connaît un lent effondrement de la pensée critique en raison de la dépendance à l'IA. Les outils mêmes censés augmenter l'intelligence humaine pourraient diminuer notre capacité à distinguer les faits de la fiction — précisément la capacité que nous devons inculquer aux machines apprenantes.
Ce n'est plus seulement un exercice académique — c'est un impératif existentiel. Et ce n'est qu'une pièce d'un puzzle de sécurité bien plus vaste qui comprend s'assurer que les systèmes d'IA poursuivent des objectifs et des valeurs humains ; maintenir une supervision humaine significative à mesure que les capacités augmentent ; prévenir les préjudices immédiats comme les abus et les violations de la vie privée ; et aborder les dangers potentiels des systèmes superintelligents aux objectifs mal alignés.
Nous parlons d'enseigner la pensée critique aux machines — déterminer la vérité du mensonge — dans un monde où nous, humains, pouvons à peine nous mettre d'accord sur ce qui est vrai. C'est un défi extraordinairement difficile. Nous devons nous assurer que nous ne créons pas de systèmes d'apprentissage continu avant de comprendre comment les aider à distinguer la vérité des mensonges. Si nous échouons dans cette tâche, la prochaine étape de l'évolution technologique de l'humanité pourrait être compromise de manière irréversible.
Au fond, nous sommes confrontés à l'une des questions philosophiques les plus profondes que l'humanité ait jamais affrontées : Qu'est-ce que la vérité, et comment pouvons-nous apprendre à une machine à la reconnaître ?
Le problème le plus difficile en matière de sécurité de l'IA n'est pas d'empêcher les systèmes de dire des choses dangereuses aux humains — c'est d'empêcher les systèmes d'apprendre des choses dangereuses et de croire qu'elles sont vraies.
Conclusion
Le problème le plus difficile en matière de sécurité de l'IA n'est pas d'empêcher les systèmes de dire des choses dangereuses aux humains — c'est d'empêcher les systèmes d'apprendre des choses dangereuses et de croire qu'elles sont vraies.
Le chemin vers l'AGI ne nécessite pas de percées mystérieuses ou de technologies de science-fiction. Les fondations existent déjà dans nos architectures d'IA actuelles, bien que des défis importants subsistent. Ce qui manque n'est pas une intuition magique ou une puissance de calcul inaccessible — c'est un cadre soigneusement conçu pour l'apprentissage continu et la vérification fiable de la vérité.
Loin d'être dans une bulle, nous nous tenons au seuil de la transformation la plus profonde de l'histoire humaine. La question n'est pas si nous atteindrons l'AGI, mais quand — et si nous aurons résolu le problème critique de la vérification de la vérité avant d'y arriver.
Ce n'est pas une hyperbole — c'est la réalité brutale de notre époque. La révolution de l'IA n'arrive pas ; elle est là. Et les décisions que nous prendrons dans les prochaines années détermineront si elle propulse l'humanité vers des sommets inimaginables ou nous mène sur un chemin que nous pourrions profondément regretter.
Le temps de la complaisance est révolu. Nous devons affronter ces défis avec l'urgence et le sérieux qu'ils méritent. Car en ce qui concerne l'AGI, nous n'aurons peut-être qu'une seule chance de bien faire les choses.